ElasticSearch 数据迁移工具elasticdump
一、安装node
首先获取安装包
wget https://nodejs.org/dist/v16.14.0/node-v16.14.0-linux-x64.tar.xz
tar axf node-v16.14.0-linux-x64.tar.xz -C /usr/local/
mv /usr/local/node-v16.14.0-linux-x64 /usr/local/node
然后配置环境变量
vim /etc/profile
export NODE_HOME=/usr/local/node
export PATH=$NODE_HOME/bin:$PATH
接下来刷新环境变量,然后测试一下安装是否完成
source /etc/profile
node -v
npm -v
如果是mac 的话可以使用brew 安装
brew install node@16
二、在线安装elasticdump
执行下面的命令安装
npm install elasticdump -g
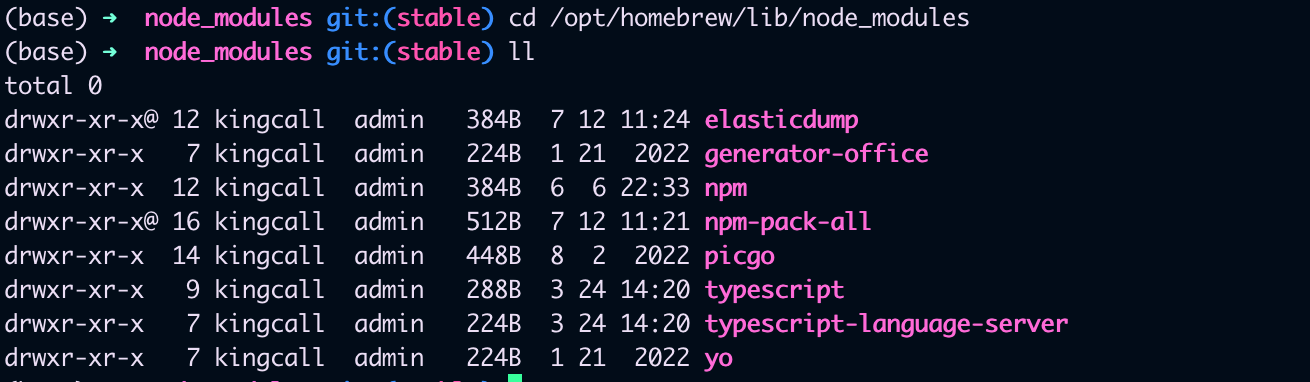
使用下面的命令查看安装目录
npm root -g
我的位置在这里/opt/homebrew/lib/node_modules
三、离装elasticdump
这里的原理是将node安装包和elasticdump安装报复制到需要离线安装的服务器。
- 获取node 的离线安装包进行安装即可,参考第一步
- 获取elasticdump的安装包安装,所以我们首选需要一个打包工具
npm install -g npm-pack-all
然后我们切换到上面elasticdump的安装路,打包elasticdump,会在当前目录生成elasticdump-6.103.0.tgz 这样一个压缩包,这就是我们离线安装需要的包
cd /opt/homebrew/lib/node_modules/elasticdump/
npm-pack-all
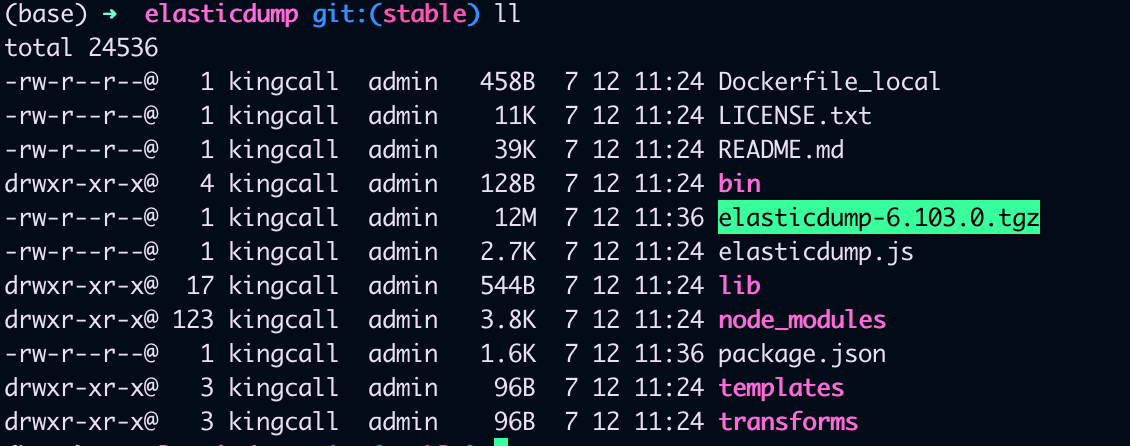
到这里我们看到离线包已经生成好了,接下来我们复制到我们之前已经安装好node 的机器上,执行下面的命令
npm install elasticdump-6.103.0.tgz
后面为了方便使用,我们可以配置一下elasticdump的环境变量
vim ~/.bashrc
# 追加以下内容
#node
export DUMP_HOME=/opt/homebrew/lib/node_modules/elasticdump/
export PATH=$DUMP_HOME/bin:$PATH
# 刷新
source ~/.bashrc
四、使用elasticdump
这里的使用主要分为两种,一种是数据备份,一种是数据迁移
- 备份主要指的是生成备份的数据文件,在需要的时候进行还原
- 数据迁移是指将原来索引里的数据迁移到新的索引
其实数据备份也能达到数据迁移的目的,但是在两个环境的网络不通的时候我们只能使用数据备份
我们安装成功后,在elasticdump的bin目录下其实有两个工具,一个是elasticdump 另外一个是multielasticdump

数据迁移
迁移索引
elasticdump \
--input=http://192.168.1.140:9200/source_index \
--output=http://192.168.1.141:9200/target_index \
--type=mapping
迁移数据
elasticdump \
--input=http://192.168.1.140:9200/source_index \
--output=http://192.168.1.141:9200/target_index \
--type=data \
--limit=2000 # 每次操作的objects数量,默认100,数据量大的话,可以调大加快迁移速度
数据备份
导出索引和数据
elasticdump \
--input=http://192.168.1.140:9200/source_index \
--output=/data/source_index_mapping.json \
--type=mapping
elasticdump \
--input=http://192.168.1.140:9200/source_index \
--output=/data/source_index.json \
--type=data \
--limit=2000
导入索引和数据
elasticdump \
--input=/data/source_index_mapping.json \
--output=http://192.168.1.141:9200/source_index \
--type=mapping
elasticdump \
--input=/data/source_index.json \
--output=http://192.168.1.141:9200/source_index \
--type=data \
--limit=2000
其他用法
还有其他使用的细节,例如压缩,指定query 什么的,我们可以参考下面的例子
# Copy an index from production to staging with analyzer and mapping:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=analyzer
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=mapping
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=http://staging.es.com:9200/my_index \
--type=data
# Backup index data to a file:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index_mapping.json \
--type=mapping
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--type=data
# Backup and index to a gzip using stdout:
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=$ \
| gzip > /data/my_index.json.gz
# Backup the results of a query to a file
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=query.json \
--searchBody="{\"query\":{\"term\":{\"username\": \"admin\"}}}"
# Specify searchBody from a file
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=query.json \
--searchBody=@/data/searchbody.json
# Copy a single shard data:
elasticdump \
--input=http://es.com:9200/api \
--output=http://es.com:9200/api2 \
--input-params="{\"preference\":\"_shards:0\"}"
# Backup aliases to a file
elasticdump \
--input=http://es.com:9200/index-name/alias-filter \
--output=alias.json \
--type=alias
# Import aliases into ES
elasticdump \
--input=./alias.json \
--output=http://es.com:9200 \
--type=alias
# Backup templates to a file
elasticdump \
--input=http://es.com:9200/template-filter \
--output=templates.json \
--type=template
# Import templates into ES
elasticdump \
--input=./templates.json \
--output=http://es.com:9200 \
--type=template
# Split files into multiple parts
elasticdump \
--input=http://production.es.com:9200/my_index \
--output=/data/my_index.json \
--fileSize=10mb
# Import data from S3 into ES (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input "s3://${bucket_name}/${file_name}.json" \
--output=http://production.es.com:9200/my_index
# Export ES data to S3 (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input=http://production.es.com:9200/my_index \
--output "s3://${bucket_name}/${file_name}.json"
# Import data from MINIO (s3 compatible) into ES (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input "s3://${bucket_name}/${file_name}.json" \
--output=http://production.es.com:9200/my_index
--s3ForcePathStyle true
--s3Endpoint https://production.minio.co
# Export ES data to MINIO (s3 compatible) (using s3urls)
elasticdump \
--s3AccessKeyId "${access_key_id}" \
--s3SecretAccessKey "${access_key_secret}" \
--input=http://production.es.com:9200/my_index \
--output "s3://${bucket_name}/${file_name}.json"
--s3ForcePathStyle true
--s3Endpoint https://production.minio.co
# Import data from CSV file into ES (using csvurls)
elasticdump \
# csv:// prefix must be included to allow parsing of csv files
# --input "csv://${file_path}.csv" \
--input "csv:///data/cars.csv"
--output=http://production.es.com:9200/my_index \
--csvSkipRows 1 # used to skip parsed rows (this does not include the headers row)
--csvDelimiter ";" # default csvDelimiter is ','
常用参数
--direction dump/load 导出/导入
--ignoreType 被忽略的类型,data,mapping,analyzer,alias,settings,template
--includeType 包含的类型,data,mapping,analyzer,alias,settings,template
--suffix 加前缀,es6-${index}
--prefix 加后缀,${index}-backup-2018-03-13
总结
elasticdump是ElasticSearch提供的一个工具,我们主要可以用来完成文章来源:https://uudwc.com/A/rXRRD
- 数据备份
- 数据迁移
这一节我们主要介绍了elasticdump的安装和使用文章来源地址https://uudwc.com/A/rXRRD