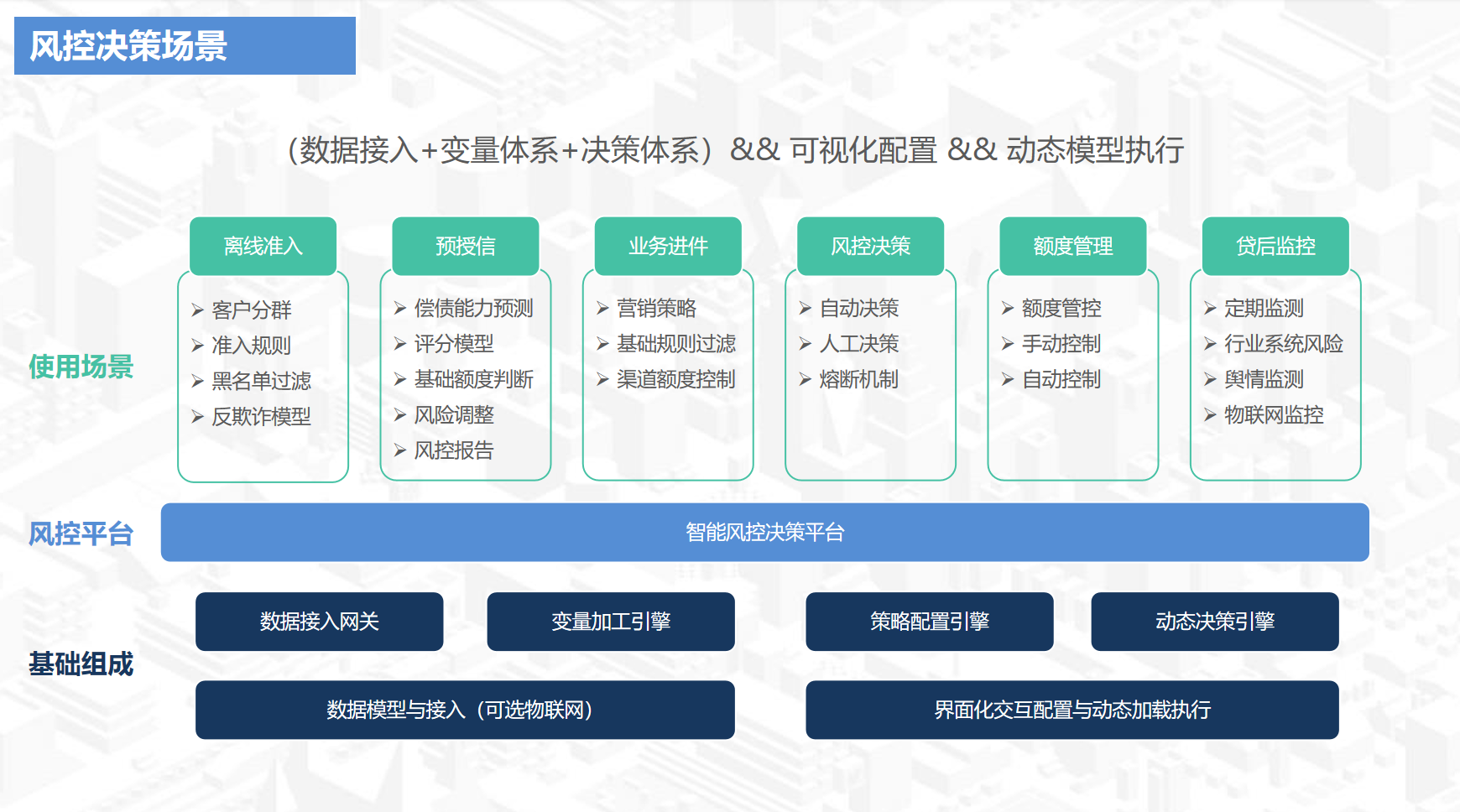
正规方程:
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes#导入数据集
from sklearn.model_selection import train_test_split #划分数据集
# sklearn.model_selection.train_test_split 是 scikit-learn 中的一个函数,
# 用于将数据集划分为训练集和测试集。
# 使用 train_test_split 函数可以将原始数据集划分为训练集和测试集,
# 以便进行模型的训练和评估。
from sklearn.preprocessing import StandardScaler#标准化处理
from sklearn.linear_model import LinearRegression#预估器
from sklearn.metrics import mean_squared_error#模型评估:均方误差
# 正规方程的优化方法对数据进行预测
# 1)获取数据
# boston=pd.read_csv('house_data.csv')
diab=load_diabetes()
# 2)划分数据集
# x=boston.drop('target',axis=1)
# y=boston['target']
x_train,x_test,y_train,y_test=train_test_split(diab.data,diab.target,random_state=22)
# print('标准化前',x_train)
# 3)标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
# print('标准化后',x_train)
# 4)预估器
estimatar=LinearRegression()
estimatar.fit(x_train,y_train)
# 5)得出模型
print('正规方程权重系数为:',estimatar.coef_)
print('正规方程偏置为:',estimatar.intercept_)
# 6)模型评估
y_predict=estimatar.predict(x_test)
print('预测值',y_predict)
error=mean_squared_error(y_test,y_predict)
print('正规方程的均方误差:',error)文章来源:https://uudwc.com/A/rZ38E
梯度下降:
import pandas as pd
import numpy as np
from sklearn.datasets import load_diabetes#导入波士顿房价数据集
from sklearn.model_selection import train_test_split #划分数据集
# sklearn.model_selection.train_test_split 是 scikit-learn 中的一个函数,
# 用于将数据集划分为训练集和测试集。
# 使用 train_test_split 函数可以将原始数据集划分为训练集和测试集,
# 以便进行模型的训练和评估。
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error
# 梯度下降的优化方法对数据进行预测
# 1)获取数据
# boston=pd.read_csv('house_data.csv')
diab=load_diabetes()
# 2)划分数据集
# x=boston.drop('target',axis=1)
# y=boston['target']
x_train,x_test,y_train,y_test=train_test_split(diab.data,diab.target,random_state=22)
# print('标准化前',x_train)
# 3)标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
# print('标准化后',x_train)
# 4)预估器
estimatar=SGDRegressor()
estimatar.fit(x_train,y_train)
# 5)得出模型
print('梯度下降权重系数为:',estimatar.coef_)
print('梯度下降偏置为:',estimatar.intercept_)
# 6)模型评估
y_predict=estimatar.predict(x_test)
print('预测值',y_predict)
error=mean_squared_error(y_test,y_predict)
print('梯度下降的均方误差:',error)文章来源地址https://uudwc.com/A/rZ38E