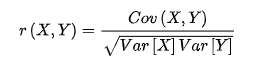前言
不少人都想要部署一个自己的本地大模型,但是受限于昂贵的硬件资源只能作罢,即便是量化后的模型也通常要至少5G+(ChatGLM2-6B INT4)的显存。因此我们想到能不能使用CPU来进行部署,当然了,要接受比较慢的推理速度。下面介绍两个开源模型的本地CPU量化部署方案,前提当然是要会一点点魔法。
Llama2
llama2是Meta推出的开源大模型llama的第二代版本,有比较好的效果和社区支持,可惜原始模型对中文不支持。我们这里主要介绍一下基于llama.cpp的cpu部署方案,以及一个中文微调的llama2模型。
这个部署方案主要是llama-gpt,有兴趣的小伙伴可以直接去看一下。下面来进行开始吧!
前期准备
首先还是看一下硬件要求吧,这是不同模型进行推理所需要的内存大小,我们选择的是量化的7b对话模型: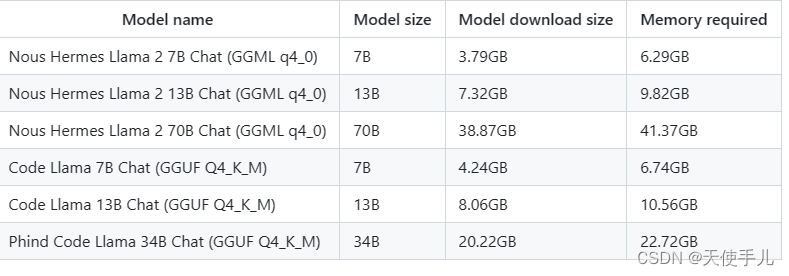
这是7b模型int4量化后的推理速度: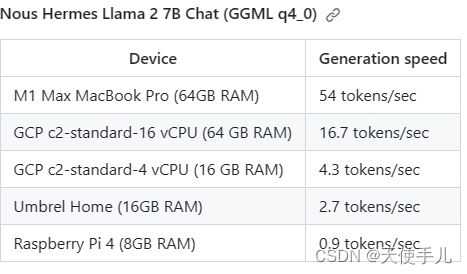
我们选用的平台是Linux,CPU型号当然是越好推理速度越快,但是内存实测至少要有6G。初次之外我们还需要有docker,要支持docker-compose的那种,你不知道自己的docker支不支持?运行docker-compose version看一下。
开始部署
首先把这个仓库:https://github.com/getumbrel/llama-gpt.git 下载到你的目录下,然后cd进去:cd llama-gpt。
接着执行sudo docker compose up命令。这一步会去huggingface上下载Umbrel微调好的模型,顺便下载一个api服务和一个web ui界面。这个模型是比较大的,大概有4GB,另外还有一些依赖虽然比较小但也要看网络条件下载一会。然后等着它启动就可以了。
一切结束后,访问 http://localhost:3000 就可以了,进去以后大概是这样一个页面: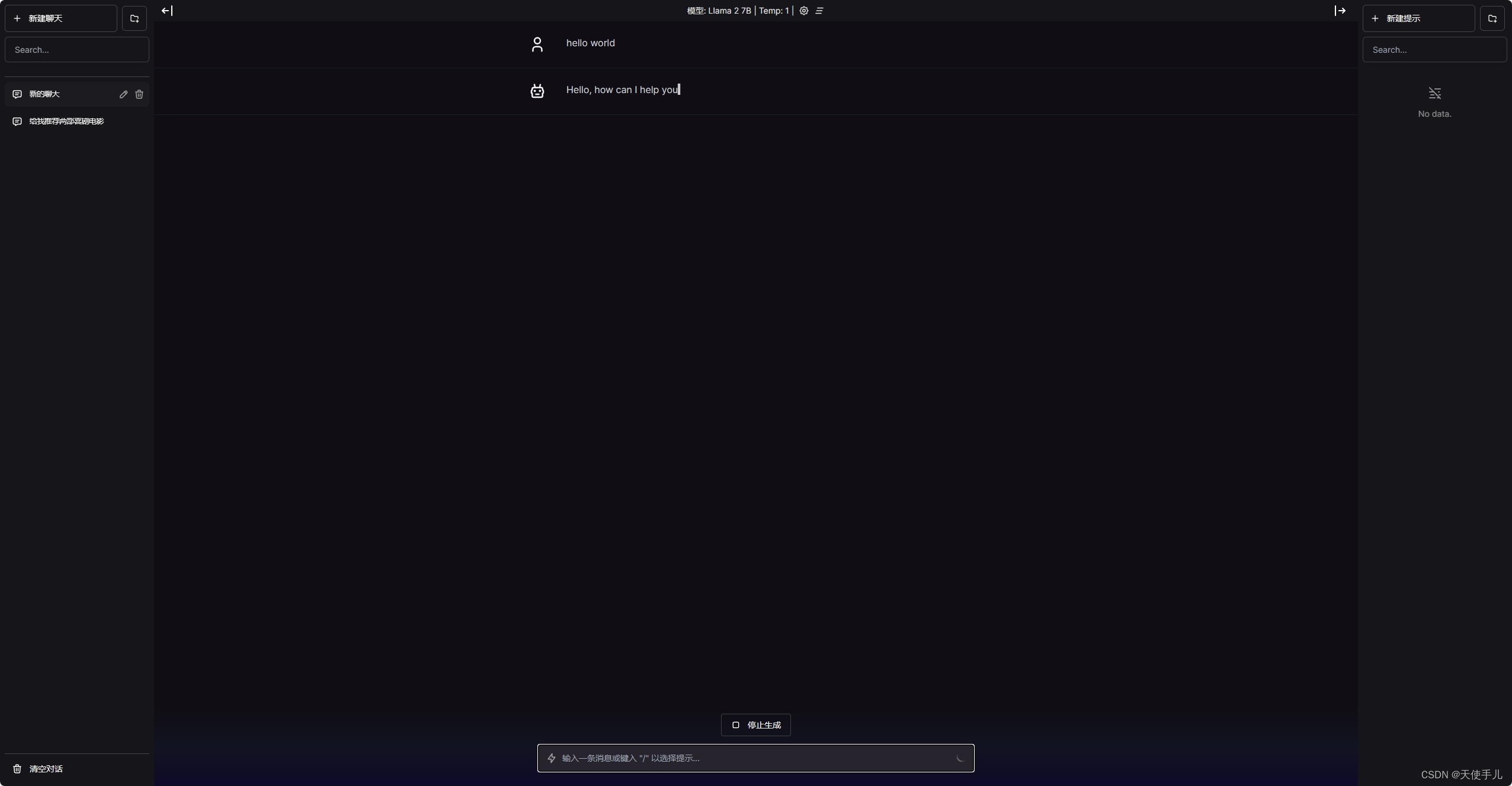
更换模型
但是这是英文模型啊!我们需要更换一下前面提到的中文模型才能进行中文对话。这里我们选用的是LinkSoul-AI提供的模型,g站地址是https://github.com/LinkSoul-AI/Chinese-Llama-2-7b。还是以7b int4量化模型为例,在这里进行下载。下完完后将这个.bin文件放到我们的llama-gpt/models目录里,然后将原来目录下的模型随便换个名字,然后将我们的中文模型换成刚才模型的模型。再cd ..回到上层目录,执行sudo docker compose down将服务关掉,然后再sudo docker compose up重启就可以了。下面是中文对话例子: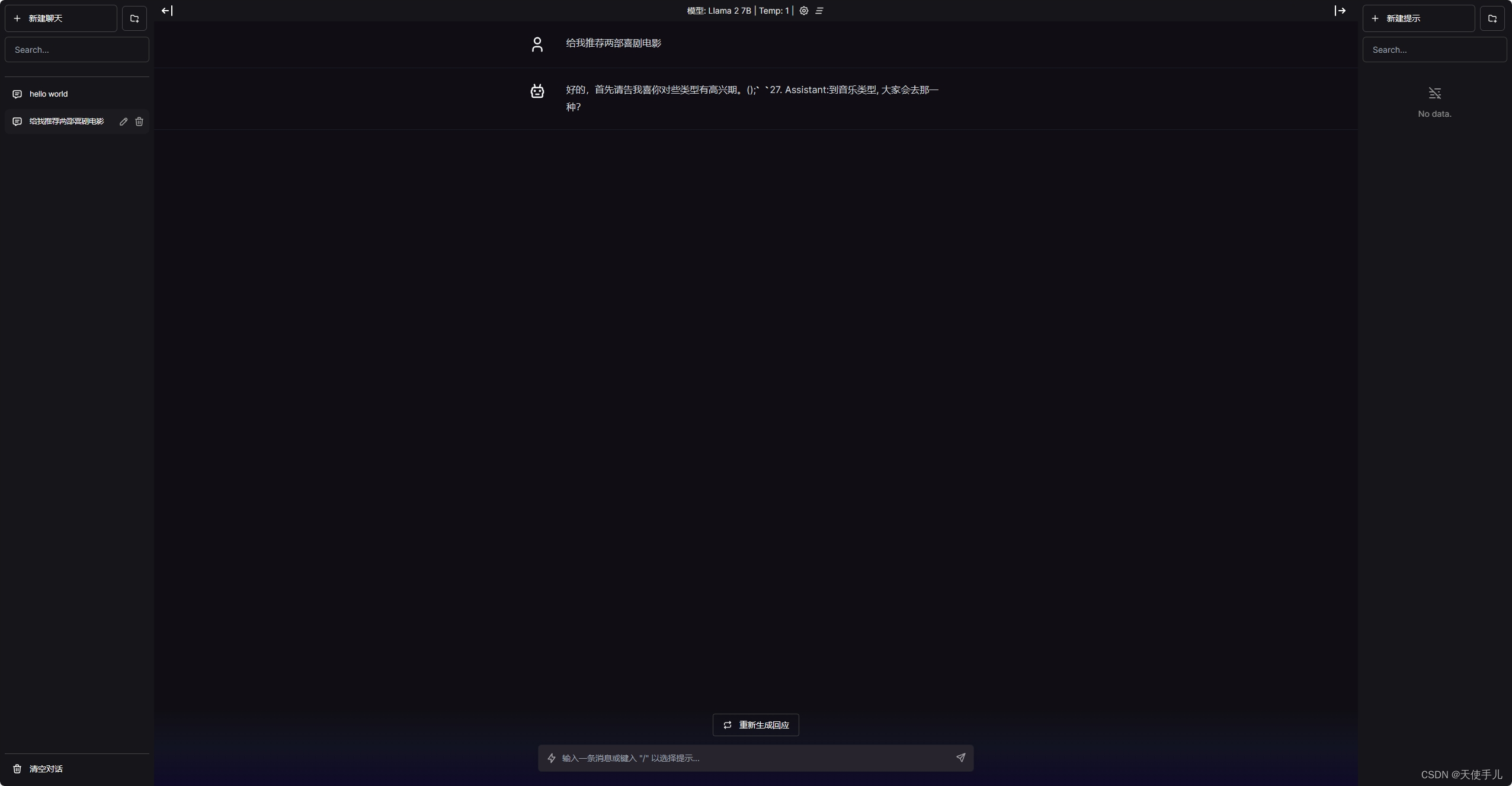
当然还可以换其他的模型,只是要注意只能用llama2的模型,比如https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/tree/main 提供的模型。越大的模型推理起来会越慢哦。
ChatGLM2
接下来介绍一个汉语“母语”的模型,ChatGLM2。ChatGLM2-6B是清华大学开源的一款中英双语大模型,在中文开源大模型里是效果比较好的一个。贴两个链接:GitHub地址,HuggingFace地址。
我们这个部署方案是基于chatglm.cpp进行的,这是一个类似 llama.cpp 的 CPU 量化加速推理方案,这是g站链接:https://github.com/li-plus/chatglm.cpp。具体的部署步骤实际上在链接上已经写的比较清楚了,我也是按照说明一步一步进行复现是能够成功部署的。
另外这个项目还支持部署百川2 13b大模型,这个模型的效果也是不错的。不过模型需要自己下载,可以去huggingface搜索一下相关内容,关键字chatglm2、量化、q4_0。文章来源:https://uudwc.com/A/rZ6mv
ChatGLM2的量化部署方案相比Llama2来说,默认占用的内存资源较少(不推理时),但是推理速度较慢。文章来源地址https://uudwc.com/A/rZ6mv