©PaperWeekly 原创 · 作者 | 李忠利
研究方向 | 自然语言处理
跟大家介绍一下自己最近训练的 LLaMA 模型——BiLLa: A Bilingual LLaMA with Enhanced Reasoning Ability.
Github 地址:
https://github.com/Neutralzz/BiLLa
HuggingFace 模型:
https://huggingface.co/Neutralzz/BiLLa-7B-LLM(语言模型 BiLLa-7B-LLM)
https://huggingface.co/Neutralzz/BiLLa-7B-SFT(指令微调模型 BiLLa-7B-SFT)
注:因 LLaMa 的使用限制,权重下载后不能直接使用,需通过脚本 [1] 转换
BiLLa 是开源的推理能力增强的中英双语 LLaMA 模型。模型的主要特性有:
较大提升 LLaMA 的中文理解能力,并尽可能减少对原始 LLaMA 英文能力的损伤;
训练过程增加较多的任务型数据,利用 ChatGPT 生成解析,强化模型理解任务求解逻辑;
全量参数更新,追求更好的生成效果。
因个人精力有限,我未能将 BiLLa 与当前主流的开源大模型进行充分的对比评测。以下是经过有限的评测分析得出的结论:
BiLLa-7B-LLM 中英语言建模能力显著优于 Chinese-LLaMA-7B [2];
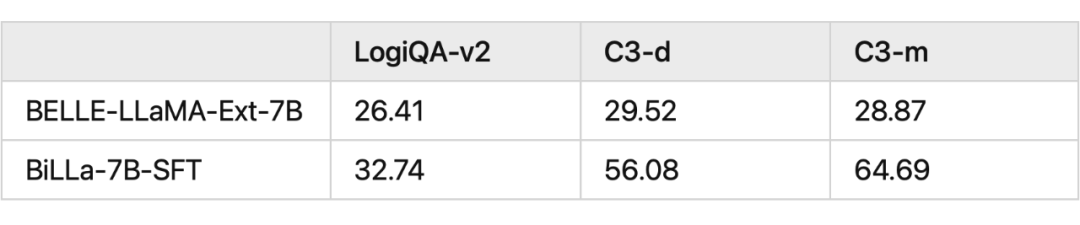
BiLLa-7B-SFT 中文推理能力显著优于 BELLE-LLaMA-Ext-7B [3] 等模型;
由 GPT4 打分,BiLLa-7B-SFT 在英文指令上得分显著高于 ChatGLM-6B [4],中文得分持平,但解题与代码得分更高。

模型训练
该模型以原始 LLaMa 模型为基础,进行了如下三个阶段的训练。
第一阶段:扩充中文词表,使用中文预训练语料 Wudao [5]、英文预训练语料 PILE [6]、翻译语料 WMT [7] 的中英数据进行二次预训练。
第二阶段:训练数据在第一阶段基础上增加任务型数据,训练过程中两部分数据保持 1:1 的比例混合。任务型数据均为 NLP 各任务的主流开源数据,包含有数学解题、阅读理解、开放域问答、摘要、代码生成等,利用 ChatGPT API 为数据标签生成解析,用于训练提升模型对任务求解逻辑的理解。
第三阶段:保留第二阶段任务型数据,并转化为对话格式,增加其他指令数据(如 Dolly 2.0 [8]、Alpaca GPT4 [9]、COIG [10] 等),进行对齐阶段的微调。
借鉴 BELLE 之前的工作 [11],三阶段的训练均为全量参数的更新,未使用 LoRA。
目前开源的模型,BiLLa-7B-LLM 是第二阶段训练完成的语言模型,BiLLa-7B-SFT 是第三阶段训练完成的指令微调模型。

模型评测
2.1 语言建模
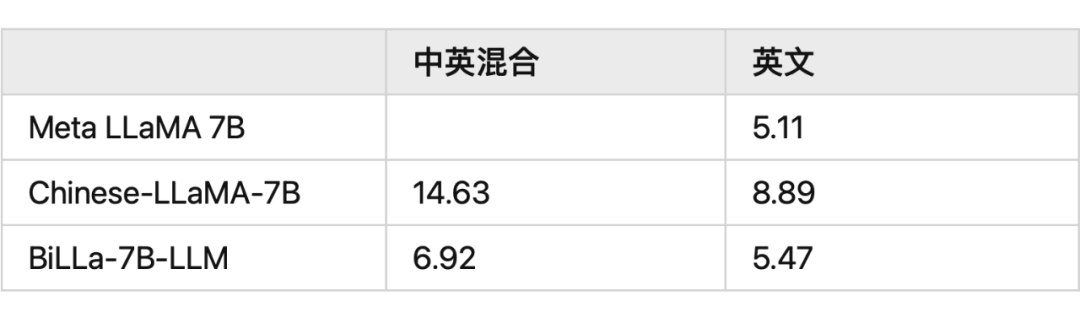
通过 Conditional Generation 评估模型的语言建模能力,在纯英文和中英混合的测试集上计算模型的 Perplexity 指标。
纯英文测试集为 1000 条 PILE 语料,中英混合测试集为 1000 条 PILE 加 1000 条 WuDao 语料,测试集数据均未参与 BiLLa 的训练,评测指标如下(数值越低越好):
2.2 GPT4打分
将 BiLLa-7B-SFT 和 ChatGLM-6B [4] 的模型结果放在一起,由 GPT4 对比两模型结果进行打分。该评测代码基本复用了 FastChat 的评测代码 [12]。
英文评测数据来源于 FastChat 的 80 条问题 [13],中文评测数据来源于 BELLE 的 1000 条问题 [14],评测指标如下(数值越高越好):
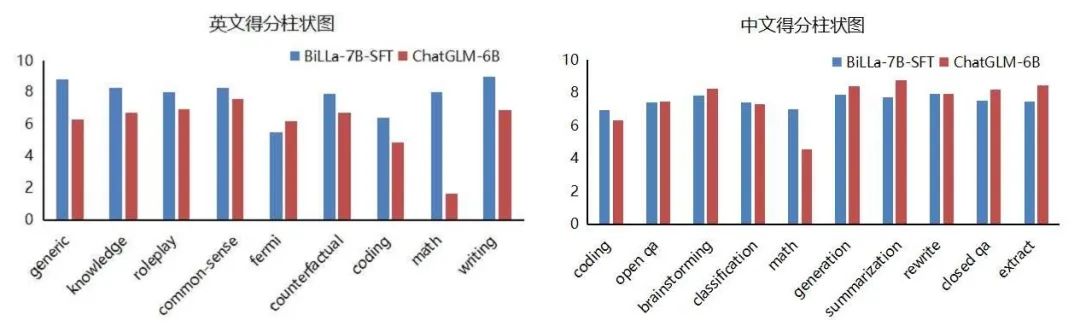
▲ GPT4打分结果
2.3 中文复杂推理
这里非常感谢学弟锴锴(PandaLLM [15] 作者)协助完成复杂推理的评测工作!
评测集采用 LogiQA-v2 [16] 与 C3 [17],两数据集均未参与 BiLLa 的训练,评测指标如下(数值越高越好):

生成示例
4.1 Case 1
Human:女朋友对男朋友说,我都和你说了 200 次了,你也不长记性,又乱买东西。请问女生对男朋友说了多少次?
Assistant:我不知道具体的数量,但是我可以告诉你,当一个人多次向另一个人表达相同的想法或建议时,他们可能会感到沮丧或失望。如果你希望能够与你的女朋友建立良好的沟通,那么最好的方法可能是倾听她的想法和感受,并尽力理解她的立场。这样,你们就可以一起合作,解决问题,并且在未来更好地沟通。
4.2 Case 2
Human:鸡兔同笼,头共有 10,足共有 28,请问鸡和兔各多少只?
Assistant:设鸡的数量为 x,兔的数量为 y,则有以下两个方程式:
x+y=10(因为总数为 10)
2x+4y=28(因为每只鸡有 2 只脚,每只兔有 4 只脚)
将第一个方程式改写为 x=10-y,代入第二个方程式中:
2(10-y) + 4y = 28
化简得
-2y+20=28
-2y=-8
y=4
将 y 的值代入 x = 10-y,得到
x = 6
所以鸡的数量为 6 只,兔的数量为 4 只。
答案为 6、4。
4.3 Case 3
Human:用 Python 写一个冒泡排序算法
Assistant:这是一个简单的冒泡排序算法的 Python 实现:
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
arr = [3, 5, 2, 8, 1, 6]
bubble_sort(arr)
print("排序后的数组:")
for i in range(len(arr)):
print("%d" %arr[i])输出结果为:
排序后的数组:
1
2
3
5
6
8上面的代码中,我们定义了一个名为 bubble_sort 的函数,它接受一个整数数组作为输入。函数中,我们首先定义了一个 n 变量,用于表示数组的长度。
然后我们使用一个嵌套循环来遍历数组中的每个元素。在每一次循环中,我们将当前元素与下一个元素进行比较,如果当前元素大于下一个元素,则交换这两个元素的位置。最后,我们返回排序后的数组。
在主程序中,我们定义了一个包含若干个整数的数组,然后调用 bubble_sort 函数来对这个数组进行排序。最后,我们将排序后的数组打印出来。

模型局限性
当前 BiLLa 模型未经 RLHF 训练,泛化性有待观望。
BiLLa 训练过程中使用了较多的任务型数据,建议减少常识类的、时事类的提问。
BiLLa 训练数据中包含了多轮对话摘要数据,但未直接包含多轮对话的生成数据,因此模型多轮对话能力可能较差。

最后
欢迎各位 NLPers 试用 BiLLa,更希望能协助完善 BiLLa 评测!

参考文献
[1] https://github.com/Neutralzz/BiLLa/blob/main/embedding_convert.py
[2] https://github.com/ymcui/Chinese-LLaMA-Alpaca
[3] https://github.com/LianjiaTech/BELLE
[4] https://github.com/THUDM/ChatGLM-6B
[5] https://www.sciencedirect.com/science/article/pii/S2666651021000152
[6] https://arxiv.org/abs/2101.00027
[7] https://www.statmt.org/wmt22/translation-task.html
[8] https://github.com/databrickslabs/dolly
[9] https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM
[10] https://huggingface.co/datasets/BAAI/COIG
[11] https://arxiv.org/abs/2304.07854
[12] https://github.com/lm-sys/FastChat/tree/main/fastchat/eval
[13] https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/question.jsonl
[14] https://github.com/LianjiaTech/BELLE/blob/main/eval/eval_set.json
[15] https://github.com/dandelionsllm/pandallm
[16] https://github.com/csitfun/LogiQA2.0
[17] https://dataset.org/c3/
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
? 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
? 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·文章来源:https://uudwc.com/A/w8o6
·
 文章来源地址https://uudwc.com/A/w8o6
文章来源地址https://uudwc.com/A/w8o6