文章目录
- 一、克隆
- 二、网络配置
- 三、SSH服务配置
- 四、hadoop完全分布式配置
一、克隆
1.在虚拟机关机的状态下选择克隆
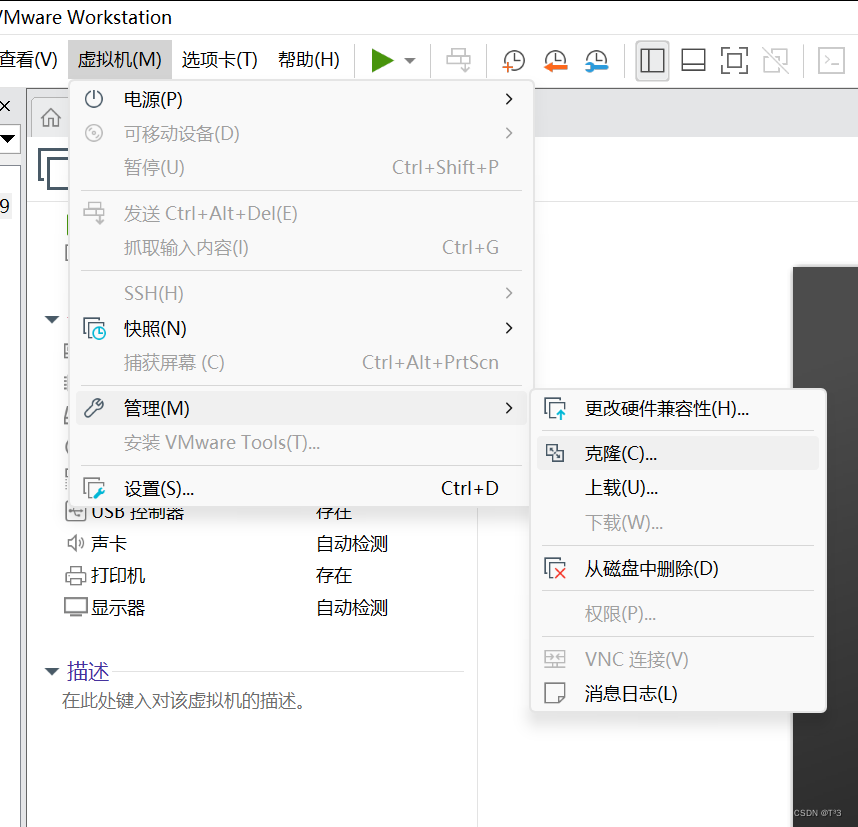
2.开始克隆

3.选择从当前状态创建

4.创建一个完整的克隆

5.选择新的虚拟机存储位置(选择内存充足的磁盘)
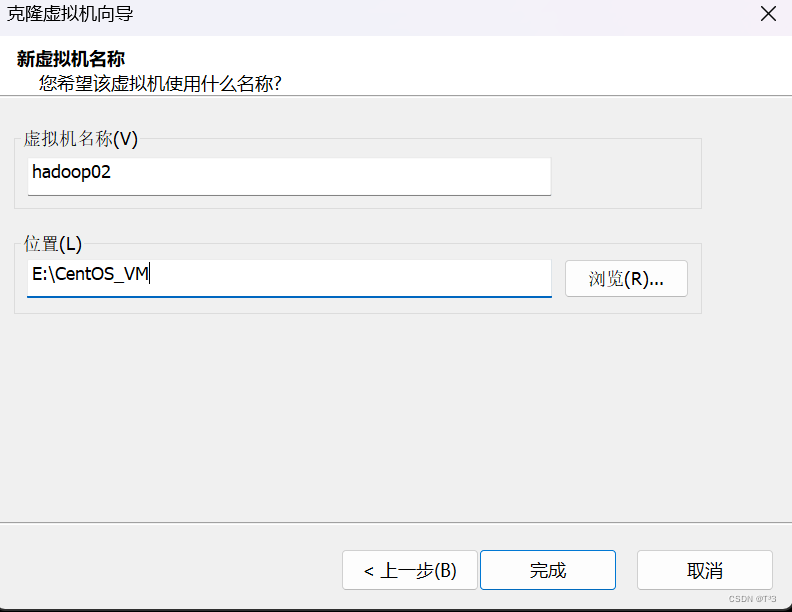
6.开始克隆
7.克隆完成
8.同样的方法克隆第二台虚拟机
9.在计算机中存在三台虚拟机
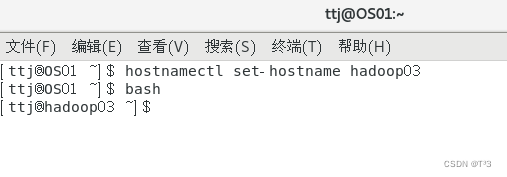
将第一台虚拟机更名为hadoop01
修改hadoop01的主机名为hadoop01

修改hadoop02的主机名为hadoop02

同样的方式修改hadoop03的主机名为hadoop03
二、网络配置
查看三台虚拟机IP地址,该地址为动态分配

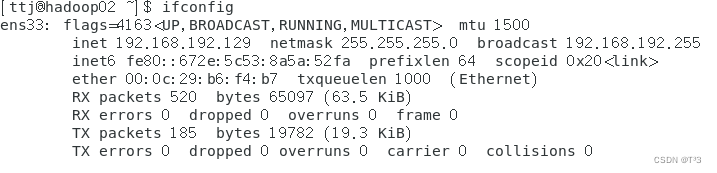
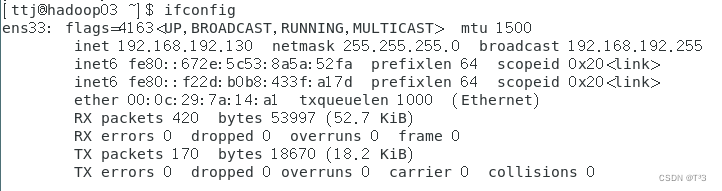
设置三台主机IP地址为固定地址:
-
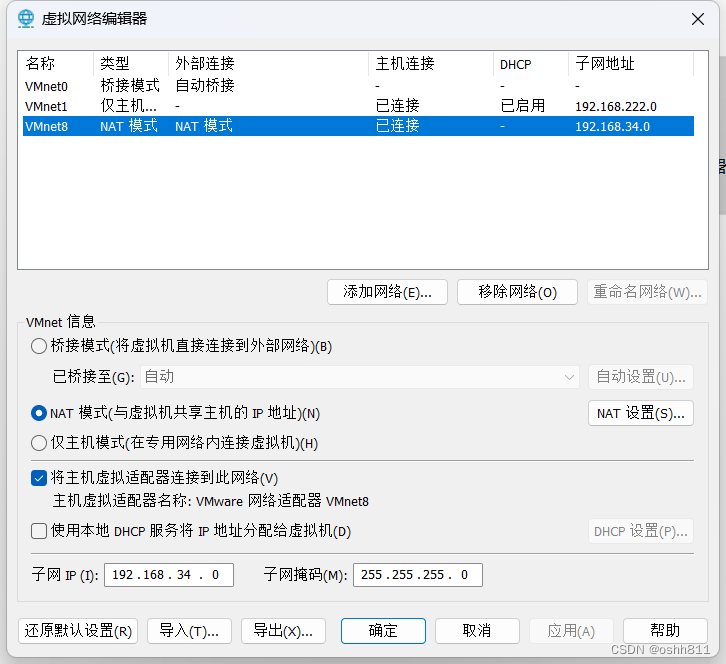
点击【编辑】——【虚拟网络编辑器】

-
【选择VMnet】模式——【NAT设置】
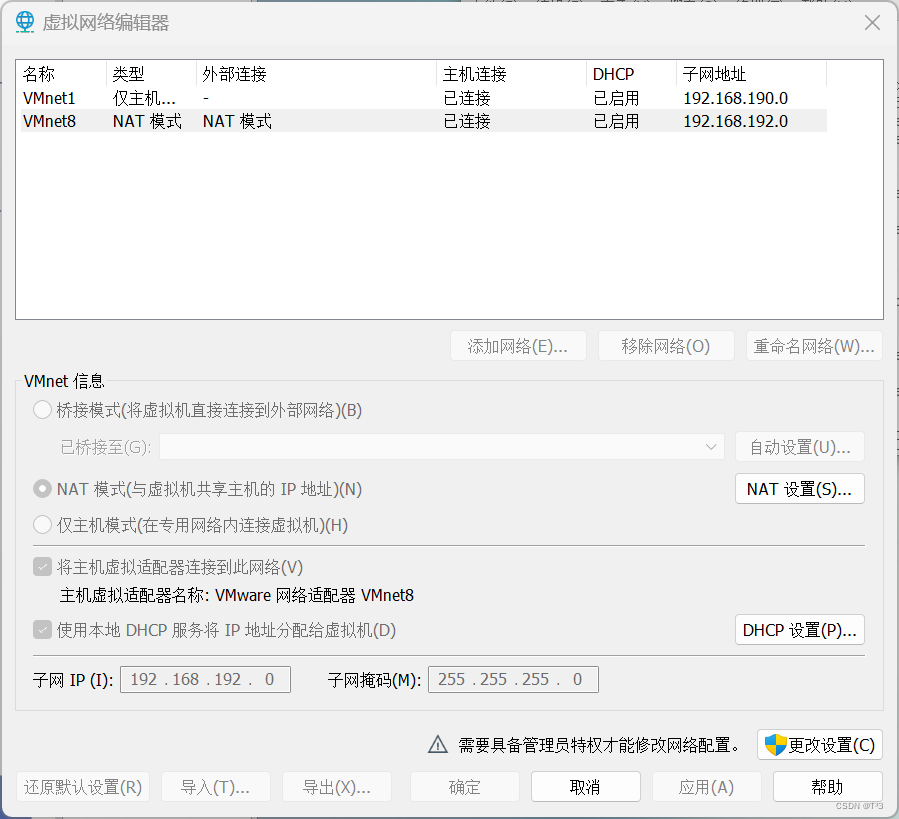
-
输入自己设置的子网IP和子网掩码
我这里设置的 子网IP:192.168.10.0
子网掩码:255.255.255.0
 hadoop01主机设置固定IP地址:
hadoop01主机设置固定IP地址:
输入命令:
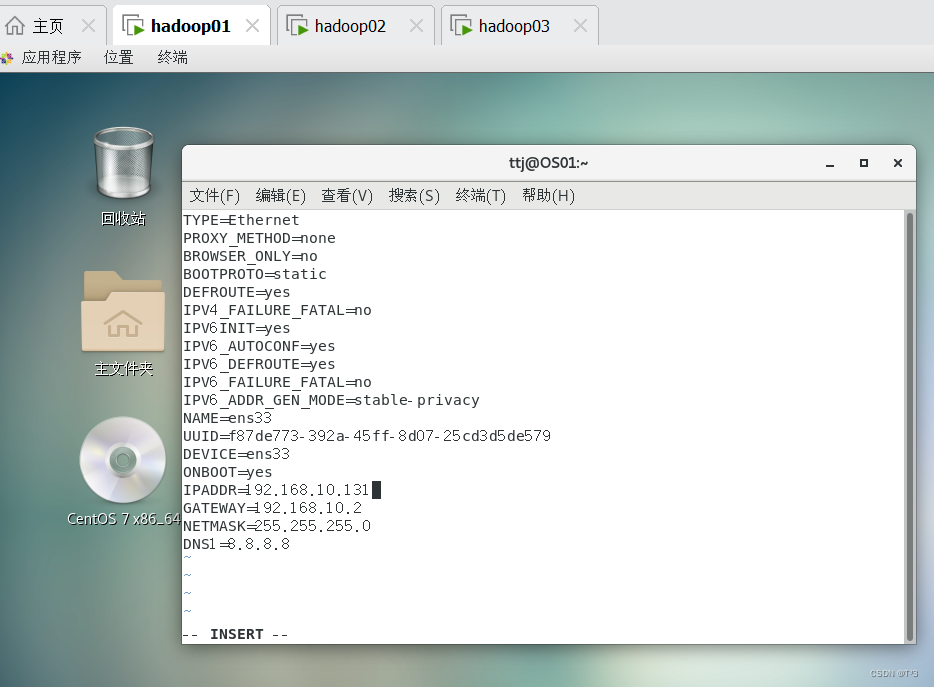
sudo vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改文件信息:
IPADDR=192.168.10.131
GATEWAY=192.168.10.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
执行命令重启网络服务:
systemctl restart network.service

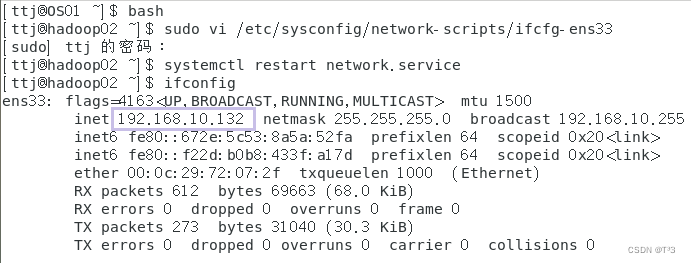
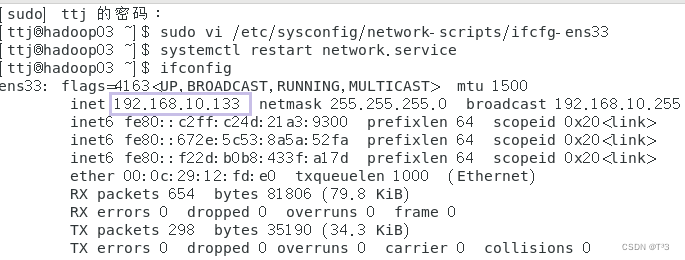
查看配置后的网络信息:
ifconfig

hadoop02和hadoop03配置方法和hadoop01方法一致
三、SSH服务配置
使用Xshell工具继续操作较为方便,所以我以下的操作均在Xshell中进行
分别连接三台主机(【新建连接】——【输入主机IP】——【连接】)
采用输入主机名称与密码的方式进行连接
成功连接三台主机

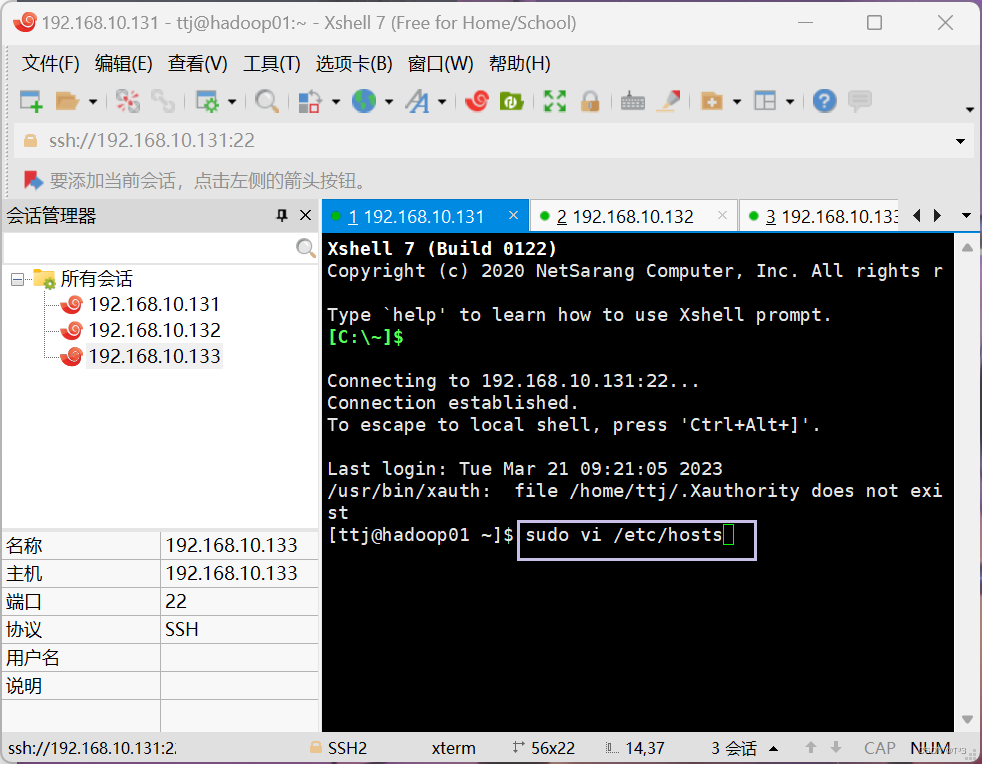
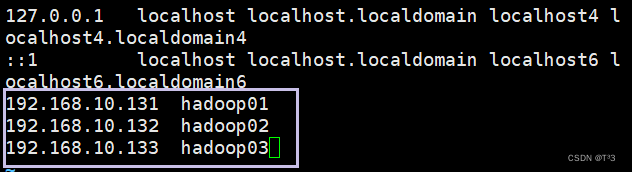
添加主机名与IP地址的映射关系
在hadoop01、hadoop02和hadoop03三台主机中分别添加主机名与IP地址的映射关系
执行命令:
sudo vi /etc/hosts
内容如下:
复制hadoop01的公钥到hadoop02和hadoop03中


验证免密码登录

四、hadoop完全分布式配置
Hadoop完全分布式配置目标:
| hadoop01 | hadoop02 | hadoop03 |
|---|---|---|
| NameNode进程 | DataNode进程 | DataNode进程 |
| ResourceManager进程 | NodeManage进程 | NodeManage进程 |
| \ | SecondaryNameNode进程 | \ |
配置主节点
进入hadoop目录下执行命令
cd /usr/local/java/hadoop-2.7.7/etc/hadoop

修改core-site.xml文件
sudo vi core-site.xml
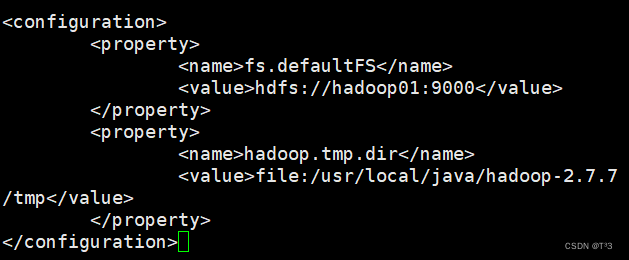
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/tmp</value>
</property>
</configuration>
修改hdfs-site.xml

sudo vi hadf-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090/</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/java/hadoop-2.7.7/dfs/data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>
修改mapred-site.xml文件

sudo vi mapred-site.xml

<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>hadoop01:9001</value>
</property>
</configuration>
修改yarn-site.xml文件

sudo vi yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8099</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
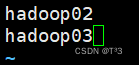
修改slaves文件
sudo vi slaves

slaves的内容如下:
在主节点hadoop01中格式化文件系统
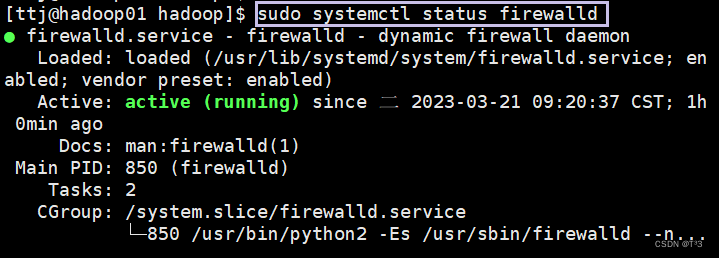
输入命令之前需要将三台主机的防火墙关闭
- 查看防火墙状态:
sudo systemctl status firewalld - 关闭防火墙:
sudo systemctl stop firewalld - 重启后还想防火墙处于关闭状态:
sudo systemctl disable firewalld
建议执行顺序:【1】——【2】——【3】
关闭前:
关闭后:
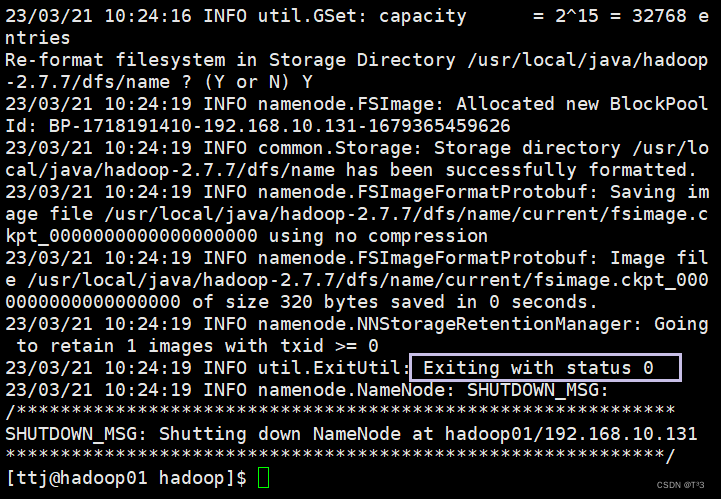
在主节点hadoop01中格式化文件系统
输入命令hdfs namenode -format或者hadoop namenode -format

集群格式化成功
分发配置文件
注意:如果是第二次或者多次执行格式化操作,在进行分发配置文件之前,需要将hadoop01、hadoop02、hadoop03下的hadoop-2.7.7/dfs目录下的name和data目录全部删掉后,再进行拷贝操作。
删除后文件夹为空:
将hadoop01节点下的hadoop-2.7.7拷贝给hadoop02和hadoop03
执行命令:
scp -r /usr/local/java/hadoop-2.7.7 hadoop02:/usr/local/java/
scp -r /usr/local/java/hadoop-2.7.7 hadoop03:/usr/local/java/

启动和查看Hadoop进程
在hadoop01节点启动服务
start-all.sh
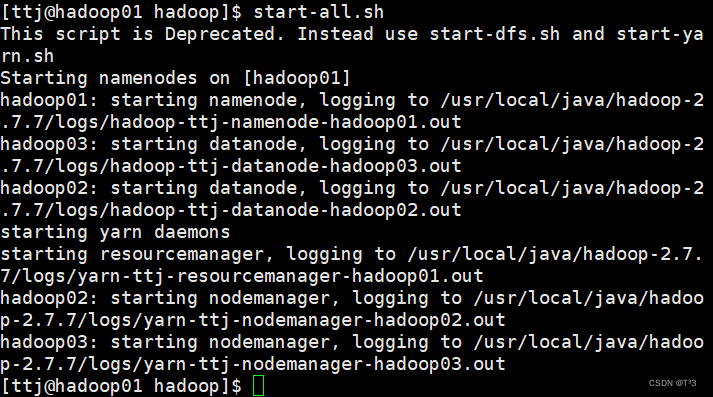
输入jsp查看进程
hadoop01节点进程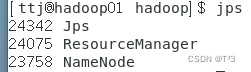
hadoop02节点进程
hadoop03节点进程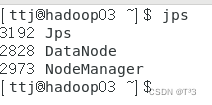
关闭所有进程:stop-all.sh
搭建过程中遇到的问题: hadoop02节点没有出现SecondaryNameNode节点,关闭集群时出现no
resourcemanager to stop、no nodemanager to stop、no namenode to stop、no
datanode to stop,但是相关进程都真实存在,并且可用。失败原因:当启动节点服务的过程中没有指定pid的存放位置,hadoop默认会放在Linux的/tmp目录下,进程名命名规则一般是框架名-用户名-角色名.pid,而默认情况下/tmp里面的东西会自动清除,因为pid不存在,所以执行stop相关命令的时候找不到pid,也就无法停止相关进程。
解决方法: 使用自定义进程存放目录
修改配置文件hadoop-env.sh 如果没有相关的配置,就直接进行添加
修改配置文件mapred-env.sh
修改配置文件yarn-env.sh
 文章来源:https://uudwc.com/A/wNywV
文章来源:https://uudwc.com/A/wNywV
以上文件配置好以后,启动hdfs和yarn,启动成功后查看jps,进程都存在,pidDir目录下有以下文件:
yarn-ttj-nodemanager.pid
yarn-ttj-resourcemanager.pid
hadoop-ttj-namenode.pid
hadoop-ttj-secondarynamenode.pid
hadoop-ttj-datanode.pid文章来源地址https://uudwc.com/A/wNywV