
开头还是介绍一下群,如果感兴趣PolarDB ,MongoDB ,MySQL ,PostgreSQL ,Redis, Oceanbase, 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共1300人左右 1 + 2 + 3 + 4) 3群即将突破 400 (目前383)会关闭自由申请,新人会进4群,另欢迎 OpenGauss 的技术人员加入。
每日感悟
我们都在追求真理,追求自由,追求公平,问题是我们都在希望别人能成为,我们理想中的人,唯独忘记了自己才是那个最刺耳的噪音。
2023年度的纽约的MongoDB local 的大会对于MongoDB的发展和当前的一些问题进行了分享,从本期会找一些有意思的话题来进行翻译。基于某些原因,可能翻译中由于能力的问题,翻译有语病或不通顺的情况,请见谅。(音译)
正文
在开始我的介绍前,我想讲一个事情,在我们工作中,一个人有多少电话的问题但是现在呢,我们有多少联系的方式。上帝知道我们下个月,有多少新的联系方式 ZOOM ID , SKAPE ID, ........


而我还使用传统的数据库来设计存储这些信息,如下面的方式二维表格,在多年前这个设计还好,我可以加一列,来记录新的联系方式,但现在我需要加多少列,才能完成这个工作。
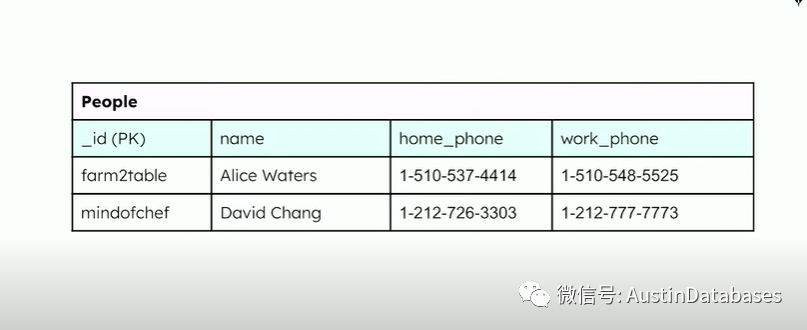
这就是我今天的Show 要和大家讨论,如何避免这样的问题与数据库建模的问题。我是 Daniel Coupal, 相信大家可以从我的博客上了解到我关于数据建模的信息和我为一些的大学开设的数据建模的课程。

今天我们有3个议题, NOSQL数据库是否需要建模,用什么技术来在MongoDB上建模,同时我们如何解决我们在使用MongoDB时遇到的一些建模的问题。
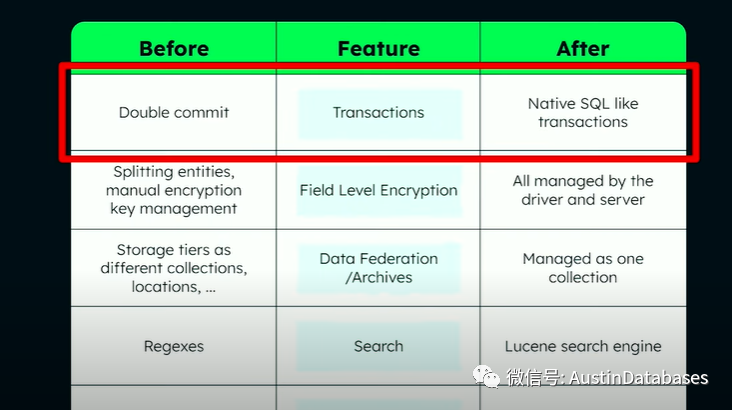
在我论述这个问题的前我想述说约束或限制的问题,(这块的内容与实际要论述的无关,所以跳过,这段主要讲授的,你在使用一个产品的时候,要深知这个产品可以提供的功能)
比如你是否熟悉关于MongoDB对于字段的加密的问题,MongoDB可以针对key:value 进行加密。
在展开我们的话题前,我还有一件事,需要说明,我们在讲解建模时需要一个案例,我们以互联网的一个有关作者和读者以及文章之间的一个模型作为讲解的对象。

在现实中,一个人写了很多的文章,一个文件有很多的评论,然后这些事情有很多的标签。但是如果我让你们来做建模这件事,可能很多人会把上面的这张图画出来,但如果到了MongoDB 则这个问题就变得复杂了,这里可以有多种建模的方式,比如第一种我们把所有的信息都放到一个collection,把所有的信息都嵌入到其中(参加下图),当然有人会说,你这样就有重复的有关于人员的信息了, 那么我们只对人员一次进行更新信息,所以我们采用第二种方案,提取所有的用户信息,然后和文章信息进行关联,那么到底那种方案是最好的。实际上这是关于你管理数据的方式问题是否能进行有效的数据更新的问题,这里如果能进行良好的数据更新,则第一个方案是更好,你只需要执行一次检索,可以获得更好的性能,但如果数据更新是一个管理的问题的话,那么第二个方案更好。

所以我们得出一个结论,如果要获得方案,首先你需要了解你的工作负载,才能更好的进行建模设计。

通过这个问题我们导入我们的今天要说的第二个部分,通过什么方法你能了解在获得你的工作负载后,进行正确的在MongoDB 中进行建模设计。

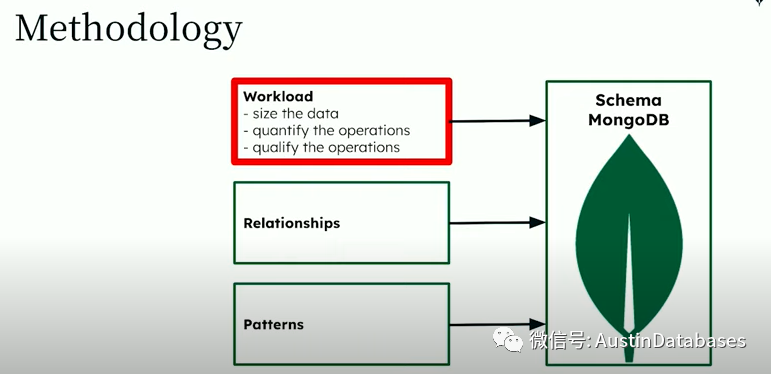
所以对于MongoDB的模式设计,首先要了解工作负载,然后是之间的关系,最后产生设计模式,最终进行建模。这里传统的设计中可能会引入建模架构师,然后互相讨论数据模型之间的关系,定义等等,然后去咖啡间喝杯咖啡,MongoDB 不同他是NOSQL,他不需要去详细的画出ER图,他非常简单,了解工作负载,然后直接进行设计。

工作负载的了解中包含了,你的数据尺寸的问题,你需要每秒操作多少次,如何进行查询,你的硬件是怎样的,想花多少费用,等等这些都是你工作负载信息中,可以了解并对你设计一个靠谱的建模有帮助的。
下面我们举一个例子,这里我们通过分析一个网站关于文章相关的数据处理来分级进行数据负载方面的分析。关于数据的吸入,我们可以看到,文章本身并不是一个高频写入的部分,而读者的comments 写入的频率明显要高于文章。从读取文件和分析读者对于文章的评估这部分来说,读取文章是一个高频的操作。但没有文章就没有我们的网站和后续的一切,所以这个部分是high, 他对我们来说太重要了。

所以这里对于我们这个项目来说,快速加载文章来说这是我们首要的工作,这里我们列出一个list ,对于我们认为重要的东西,我们需要更深层次的挖掘对我们建模有用的信息。另外还有一些信息,比如如果你和金融机构进行合作,某些约束你要了解,比如你希望你的数据保留2-3年,而实际上他们要去你要保留更长的时间10年,这样的情况下你要对数据的存储的部分也有清晰的认知。


下面我们到了第二个部分,在你对于基础的信息都了解后,你需要来定义关系,比如1 VS 1 , 1 VS N , N VS N,在设计时,你还需要考虑更多,比如类似推特,如果一个人有100万粉丝,你是不会想把这100人嵌入到这个人的document,所以这里我们可以把你需要的数据最小化处理的方式找到你应该使用的设计模式。

下面我们需要考虑的是,你是否需要嵌入的方式将这些信息放到我们的建模中,我们举例,如果我把我的车停到我的车库,如果是传统数据库,则我第二天要开车,就需要打开车库,把车辆的每个零件都找到,然后组装后,开出去(意思是获得数据还需要进行多个表的JOIN)。如果是MongoDB 我打开车库,里面就放了一辆车。

这里我们总结一下 ,如果我们想要应用程序访问数据,最好的方式是把他们放到一起。

同时关系型数据库为什么也反感 reference ,也是因为访问的成本高的原因,使用嵌入的方式避免的关联查询的问题。这里需要说明,MongoDB是讲一个实体放入到另一个实体,如果是这样的情况下如果你的一个实体非常的小,可以用数组的方式来进行嵌入的处理。
所以我们的问题是到底我们在模式设计中使用嵌入,还是,引用。我们还说刚才说的推特的问题,我们有两个体量非常大的数据,这里我们不能用嵌套的方案,N VS N ,这里我们两个比较大的实体之间,使用引用的方式,这里MongoDB 支持事务,所以这个问题很好被解决。
但这里我们需要说明的是,在两个大对象进行引用的情况下,你的内存会驻留很多引用的信息,但是使用者不要忘记MongoDB的初衷是什么,在读取一次,提供更高的效率。另从归档的角度来说,一些数据的归档,在传统数据库是一个灾难,你需要把相关的表都链接起来进行完整的数据归档,而在MongoDB 他在一个collection中。
同时你的代码也很简单,没有转换读取,从数据库中转换数据库,在进行存储的问题。


在设计中MongoDB 都提供了灵活性,嵌套,数组,链接,灵活的方式,这里我写了一本数据关于如何进行建模的设计。

这个部分的处理里面我们还可以通过分析,比如我们对于文章阅读中,对于文章的作者感兴趣,那么我们可以仅仅在articles中显示作者的名字,如果想要了解更详细的信息可以通过链接的方式,在程序中访问people这个collection来解决问题。
同时针对于comments 的处理,我们还可以通过逻辑分析来进行处理, 一个文章可能有1000多个评论,但实际上大多数人不会将1000多个评论都访问,所以我们只需要在articles 中设置一个子集,存储最后10条的评论,如果要看所有的评论可以直接访问comments collection。这样做的原因都是为了性能。

说到这里我们要进入下一个话题,evolving the model with the schema versioning .
在你成功的设计出一套建模后,并运行一段时间后,你会在应用和数据处理模式数据量变化的情况下,改变现有的建模。


在传统数据库中,默认的我们会添加字段,或者改变表和表之间的关系
下图我们有两个模式的版本,第二个版本我们建立了链接模式,


我们在周五进行部署,周一进行切换从原有的模式到新的模式中,这里包含的数据的迁移,应用的重新设计和改变,更新好数据,然后停机,进行切换。
如果这个事情换到MongoDB,我们仅仅需要在原有的文档中加入版本号,这里一个collection 有文档的多态规范,也就是一个集合中存在两个版本的数据,我们可以让每个文档都有自己的版本
还是这件事,我们在使用了MongoDB后,根本不需要停机,我们只需要更改应用程序让他可以读取版本2的数据和处理版本2模式的数据,同时还兼容版本1的数据,数据迁移和应用的使用是动态的切换。


此处省略,对上述的部分的重复和总结以及对Mongodb的大加赞扬 !

然后推荐了一本关于模式设计的书。
总结,整体里面还是介绍,并且是一些老的概念,但对于初学者来说,足够改变对于数据库模式设计的看法和思路。
文章来源:https://uudwc.com/A/xGpan
 文章来源地址https://uudwc.com/A/xGpan
文章来源地址https://uudwc.com/A/xGpan
![【C++】STL——vector的使用、 vector增删查改函数的介绍和使用、push_back和pop_back、operator[]](https://img-blog.csdnimg.cn/f2aa8fd4dc064305b95ee22cde386bdc.png)