目录
一、大数据
1、大数据架构
2、大数据技术生态
3、Lambda架构
4、Kappa架构
5、Lambda架构与Kappa架构对比
一、大数据
1、大数据架构
大数据是指其大小或复杂性无法通过现有常用的软件工具,以合理的成本并在可接受的时限内对其进行捕获、管理和处理的数据集。这些困难包括数据的收入、存储、搜索、共享、分析和可视化。
5个V:大规模(Volume)、高速度(Velocity)、多样化(Variety)、价值密度低(Value)、真实性(Veracity)
大数据的应用领域:制造业的应用、服务业的应用、交通行业的应用、医疗行业的应用等。
大数据面临着5个主要问题,分别是异构性(Heterogeneity)、规模(Scale)、时间性(Timeliness)、复杂性(Complexity)和隐私性(Privacy)。
大数据研究工作将面临5个方面的挑战:
(1)挑战一:数据获取问题。
(2)挑战二:数据结构问题。
(3)挑战三:数据集成问题。
(4)挑战四:数据分析、阻止、抽取和建模是大数据本质的功能性挑战。
(5)挑战五:如何呈现数据分析的结果,并与非技术的领域专家进行交互/
建议采用成熟技术解决大数据带来的挑战,并给出了大数据分析的分析步骤,大致分为数据获取/记录、信息抽取/清晰/标注、数据集成/聚集/表现、数据分析/建模和数据解释5个主要阶段。
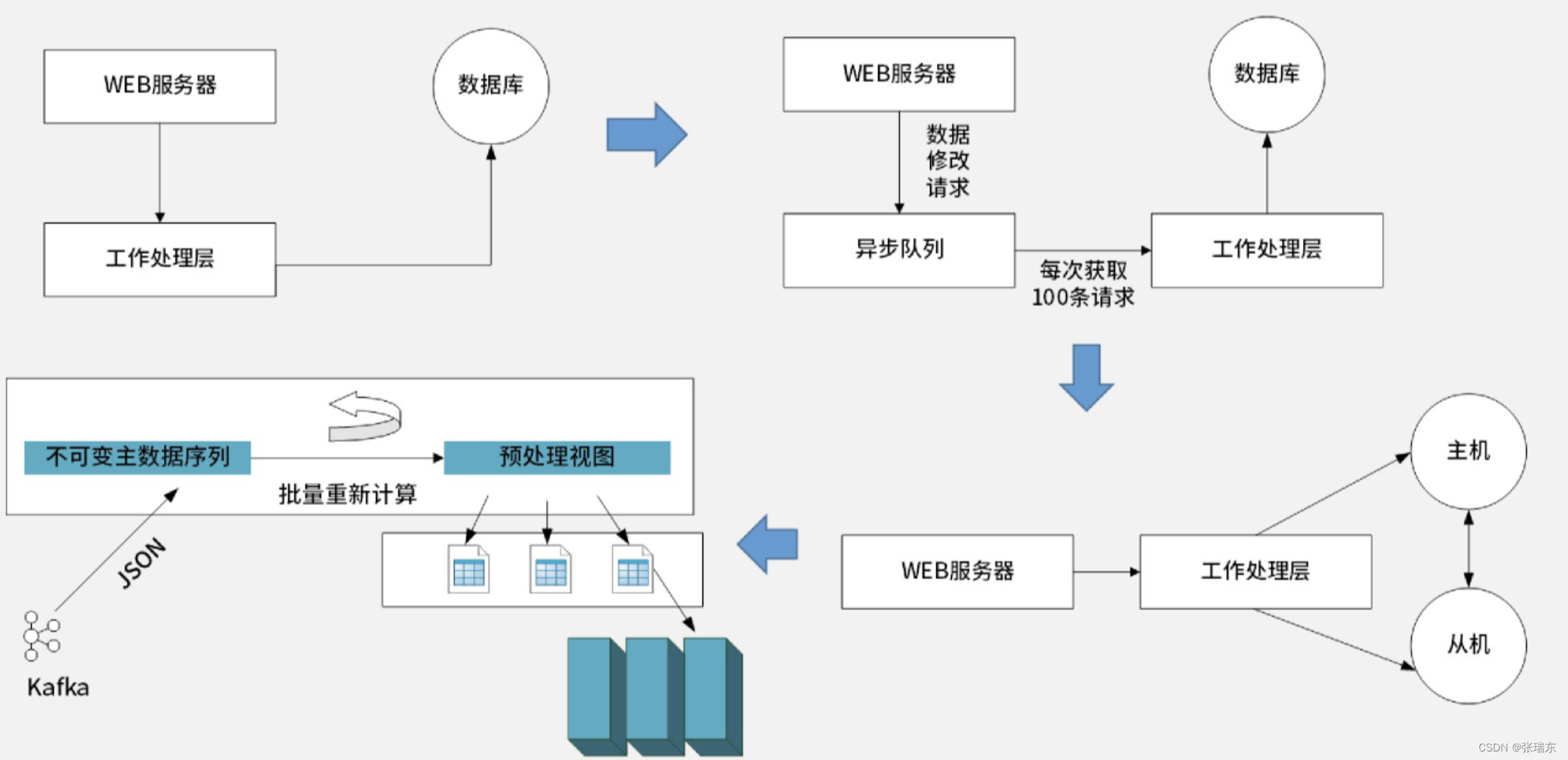
2、大数据技术生态

Hbase:分布式、面向列的开源数据库,适合于非结构化的数据存储。【实时数据和离线数据均支持】
HDFS(Hadoop分布式文件系统):适合运行在通用硬件上的分布式文件系统(Distributed File System)。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。【通常用于处理离线数据的存储】
Flume:高可用/可靠,分布式海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接收方(可定制)的能力。
Kafka:一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
ZooKeeper:开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
3、Lambda架构
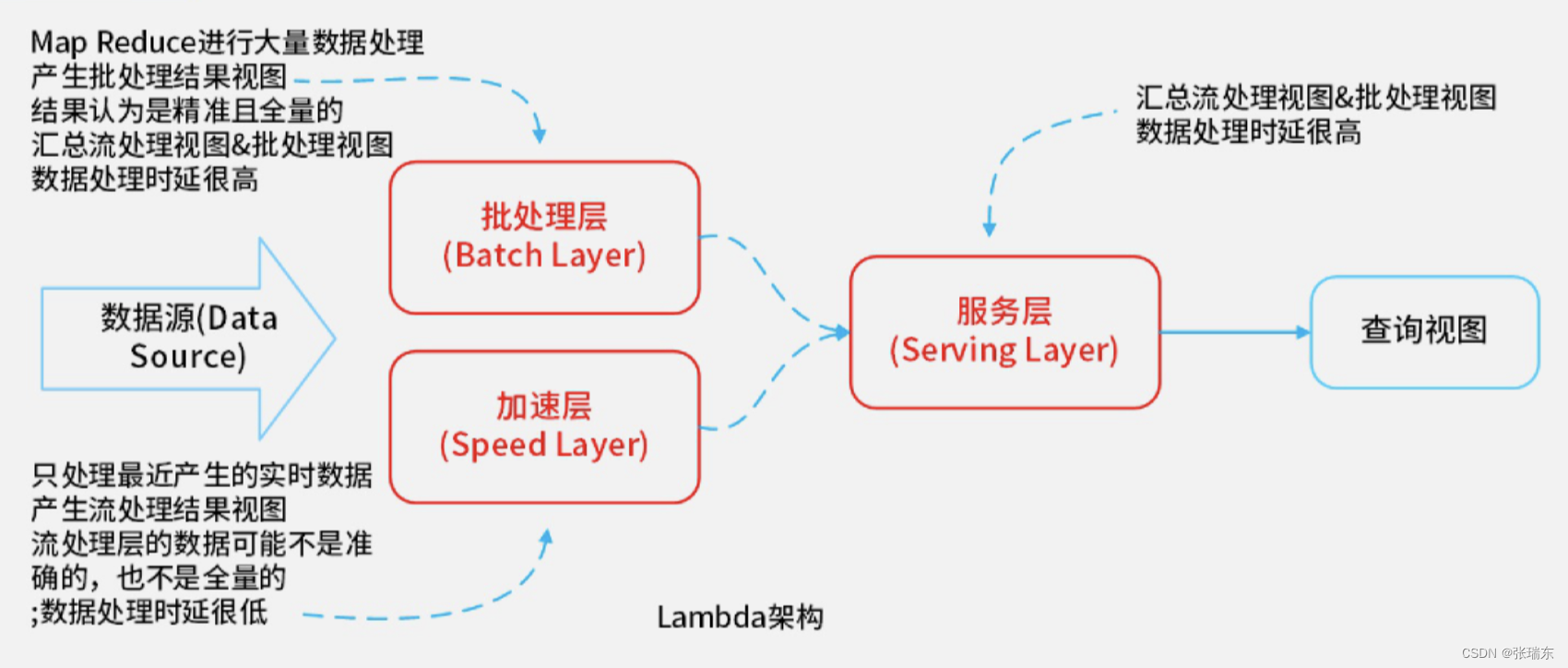
(1)批处理层(Batch Layer):两个核心功能:存储数据集和生成Batch View。
(2)加速层(Speed layer):存储实时视图并处理传入的数据流,以更新这些视图。
(3)服务层(Serving Layer):用于响应用户的查询请求,合并Batch View和Real-time View中的结果数据集到最终的数据集。
【优缺点】

4、Kappa架构
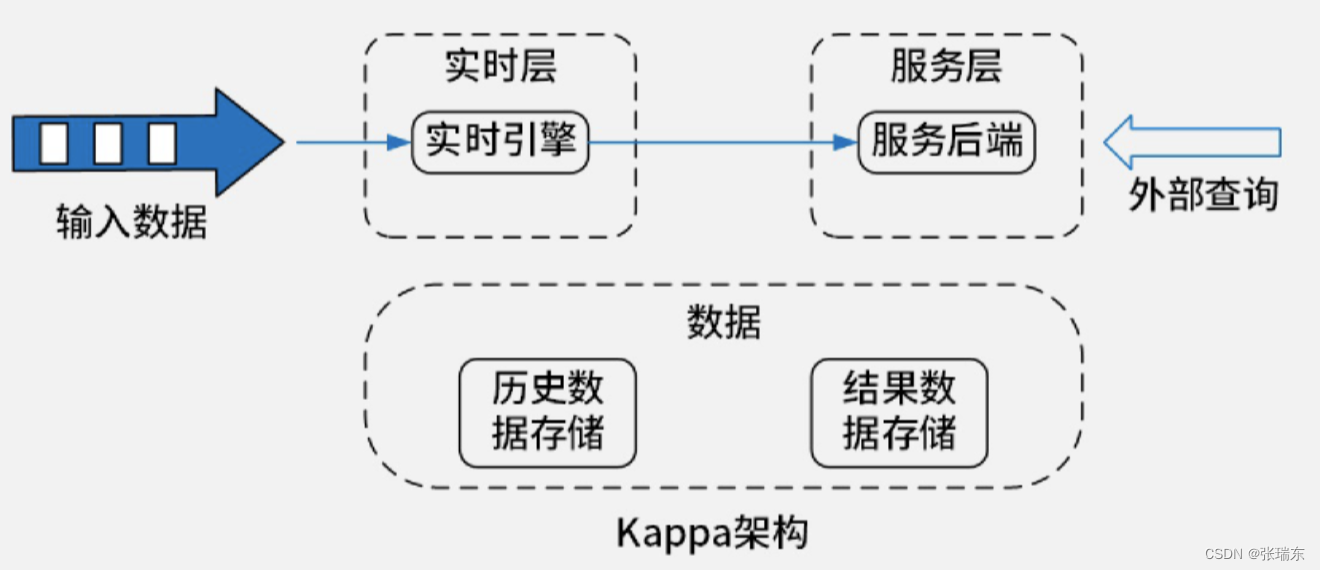
(1)输入数据直接由实时层的实时数据处理引擎对源源不断的源数据进行处理。
(2)再由服务层的服务后端进一步处理以提供上层的业务查询。
(3)而中间结果的数据都是需要存储的,这些数据包括历史数据与结果数据,统一存储在存储介质中。
【优缺点】

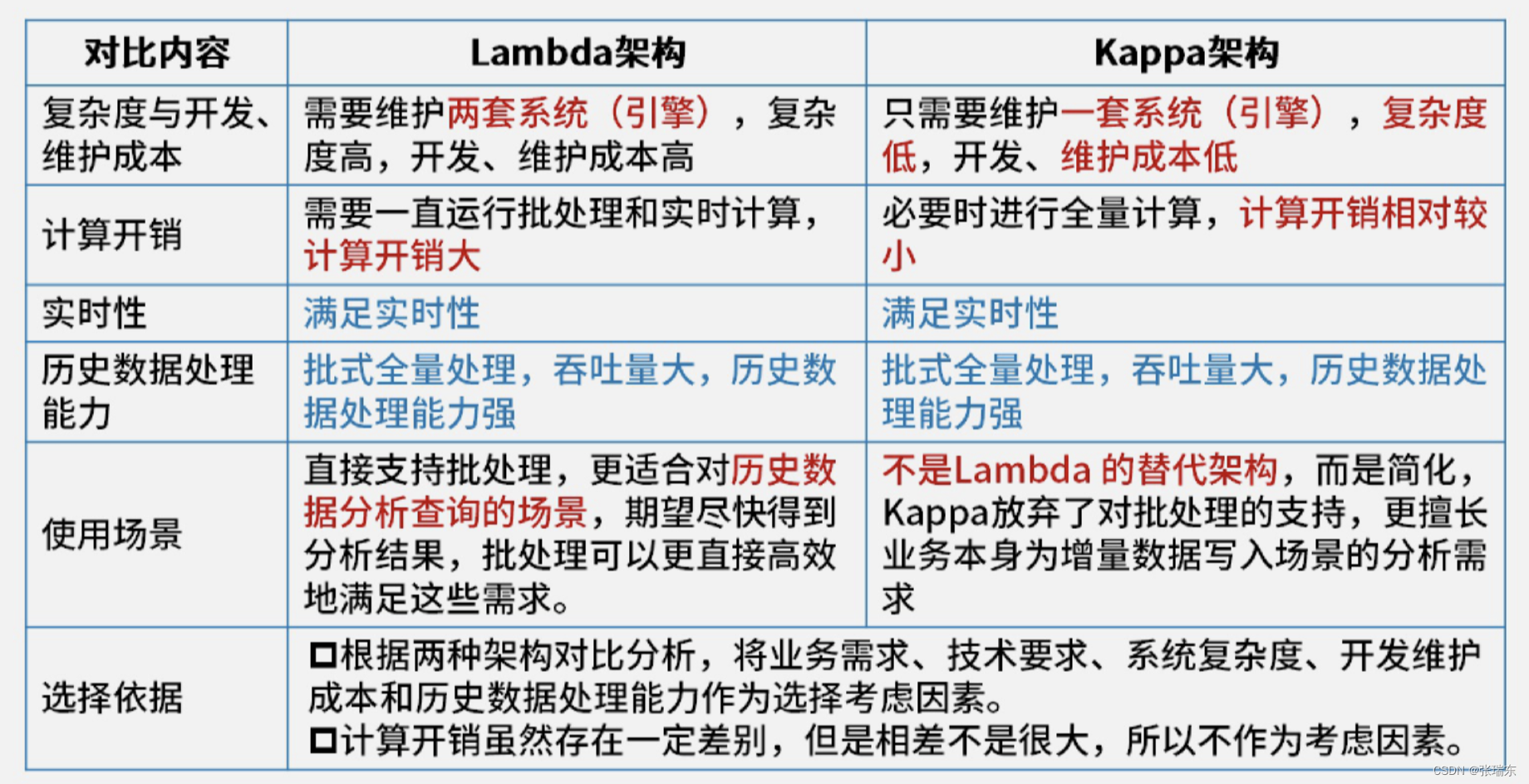
5、Lambda架构与Kappa架构对比
【某网奥运中的Lambda架构】
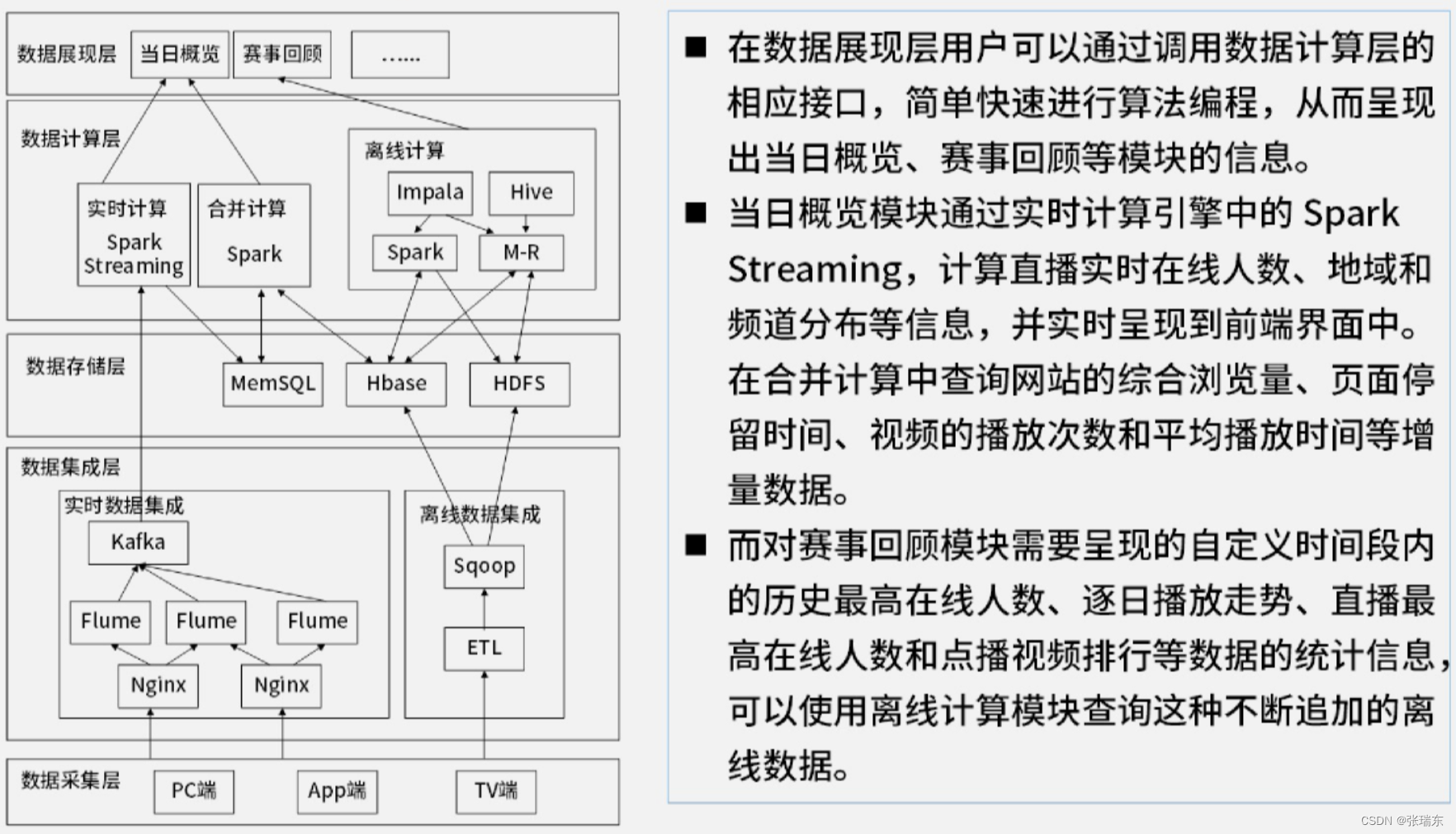
【某证券大数据系统Kappa架构】文章来源:https://uudwc.com/A/y54bW
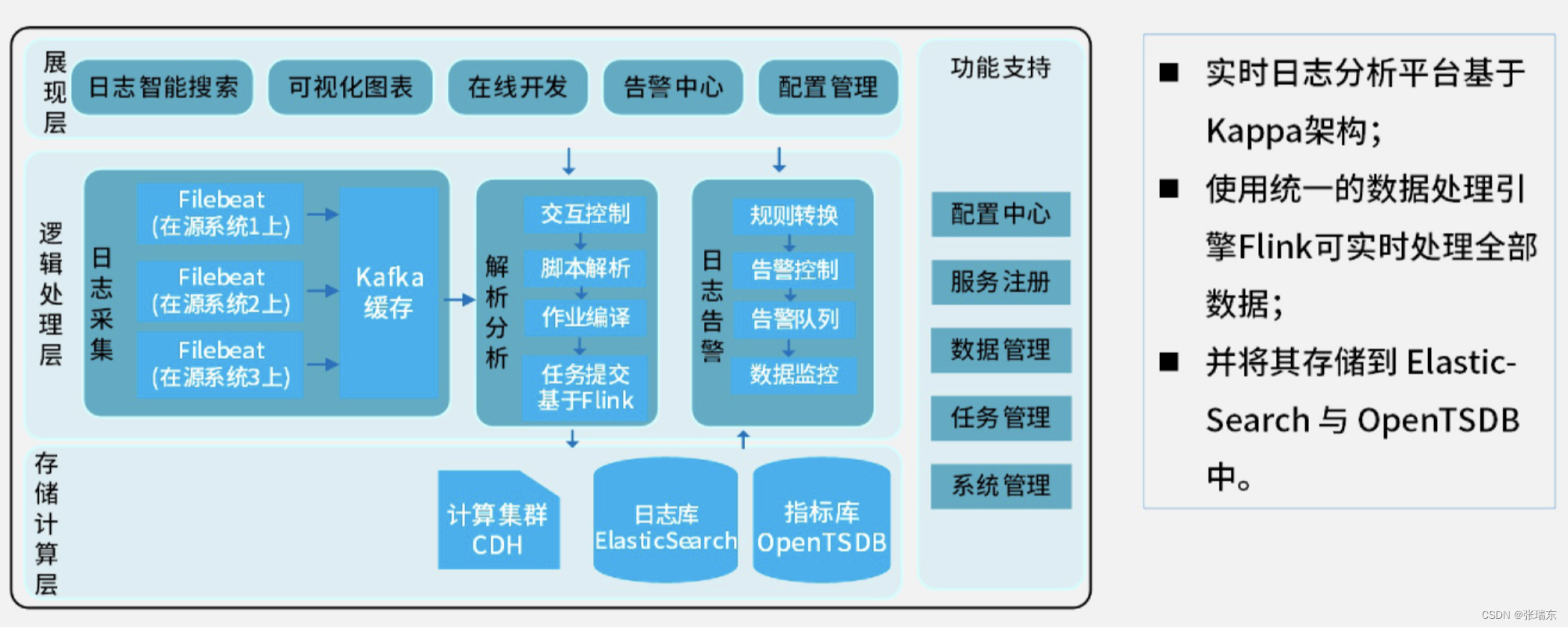 文章来源地址https://uudwc.com/A/y54bW
文章来源地址https://uudwc.com/A/y54bW
