论文地址:https://arxiv.org/pdf/2106.09685.pdf
项目地址:https://github.com/microsoft/LoRA
全文翻译地址:https://zhuanlan.zhihu.com/p/611557340 本来想自行翻译的,但最近没有空
1、关键凝练
1.1 LORA是什么?
LORA是一个解决大模型finetune的技术。现行的大模型(如GPT3,参数量175B)的训练微调成本比较高,一次训练需要几个月才能完成,这提高了nlp大模型的准入门槛。大模型finetune的目的是为了将通用领域的大模型能力迁移到专业领域(下游应用环境), 因为直接在专业领域训练nlp模型存在难以收敛的风险(nlp的专业领域应用需要通用领域的词汇嵌入支持提供初级词汇理解能力,在通用领域的大数据规模下训练后可以增强词汇嵌入能力,再进行专业领域训练。
通俗来说,LORA技术就像一个化妆技术。感觉就像一个人颜值不高(大模型到专业领域精度不足),想去做整容手术又没钱(进行迁移学习达不到硬件门槛),只能通过化妆来改变自己(对部分参数进行改进训练) .
1.2 LORA解决了什么?
1、LORA有效的降低了大模型finetune的成本,将其硬件进入门槛降低了3倍,并提升了训练效率。现行的大模型finetune技术主要有adapter layers和optimizing Some forms of the input layer activations, 这两种形式修改了原有大模型的网络细节,增加了模型参数,导致推理延时。
2、LORA技术也解决了模型部署时的能力热切换,在模型运行时仅需替换掉部分微调的参数即可实现大模型能力的切换。大摸型参数量大,如1750亿参数的GPT3的模型文件估算有800Gb(fp32),哪怕在ddr5内存中(90GB/s=12.25Gb/s),也得一分钟上才能实现切换。而LORA切换模型仅涉及其优化部分的参数替换,仅为35M
1.3 LORA的技术方案?
1、LORA认为现有的大模型针对专业领域是一个过度参数化模型参数冗余模型,实际上存在于一个较低的内在维度可以表示这个这个大模型的全部维度即存在一个低秩矩阵可指代原有的参数。LORA对低
秩参数进行训练,冻结模型的原始参数,在训练结束后再将训练好的低秩矩阵叠加到原来的参数中。类似于矩阵的奇异值分解,只对分解后的矩阵进行训练;然后将训练好的矩阵做乘法,得到最新的全尺寸参数,并叠加到原模型中。
下图既为ROLA的技术方案,其中蓝色区域表示为冻结的原始参数,橙色部分为LORA的新增参数部分(其中的d为为原始参数维度),其中A的初始化为高斯分布,B的初始化为全0(其中的r为原始参数的低秩数)。原始的参数训练量为d x d,ROLA技术的参数训练量为d x 2r。在LORA的实际操作中,BA得到的矩阵W`是通过缩放倍数后才接叠加到原有参数中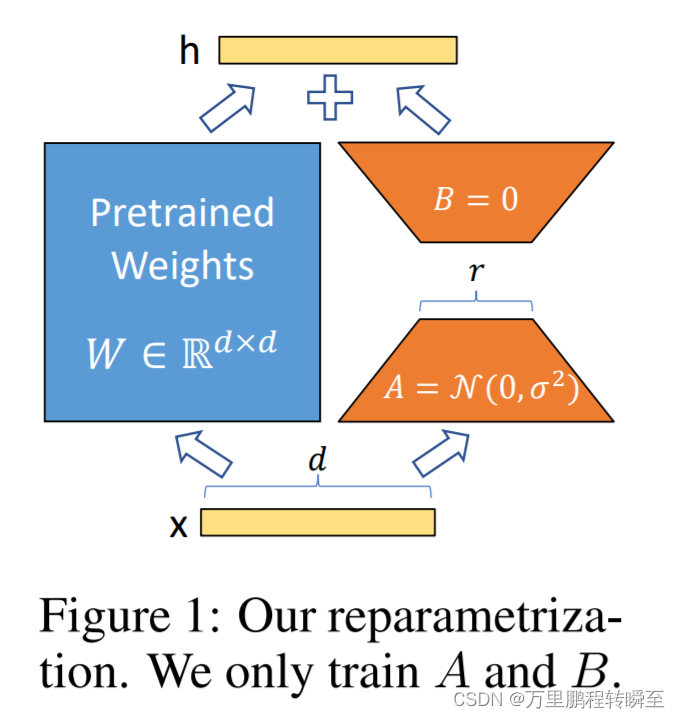
2、ROLA将参数冗余的研究目标具体到Transformer layer中,在其实验中主要针对attention模块,其对Wk、Wq、Wv和Wo都进行了低秩重构训练。其表明优化的的参数越靠近输出效果越好。LORA的实验效果表明,其只是在训练过程中放大了对下游任务有用的特征,而不是预训练模型中的主要特征。
2、原文关键
2.1 低秩参数化更新矩阵
内容参考自 https://zhuanlan.zhihu.com/p/611557340
原始的迁移学习是对
W
0
W_0
W0进行调优训练,其调优结果部分被定义为
∆
W
∆W
∆W,
∆
W
∆W
∆W与
W
0
W_0
W0具有相同的参数量。LORA将
∆
W
∆W
∆W分解为BA两个部分,假设原始W的维度为d x k,内在秩为r,则训练BA的参数量为 d x r + r x k = r x (d + k)。
2.2 LORA的实施效果
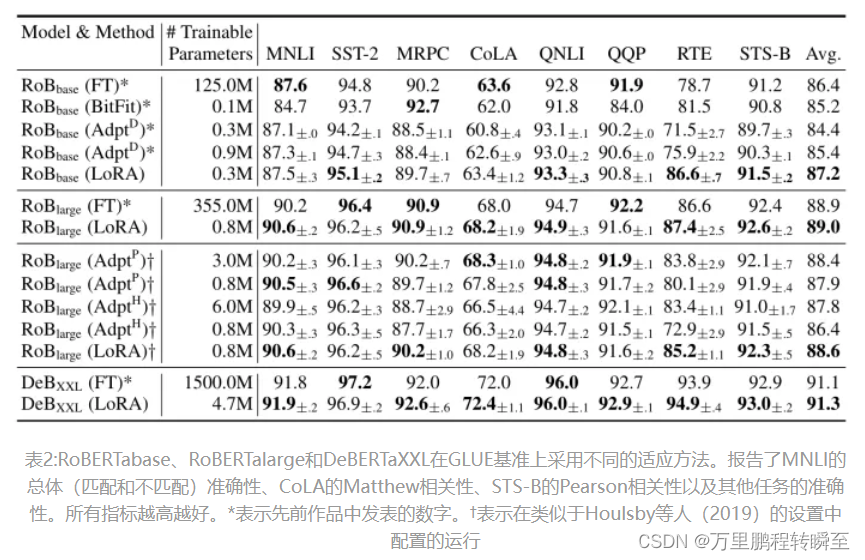
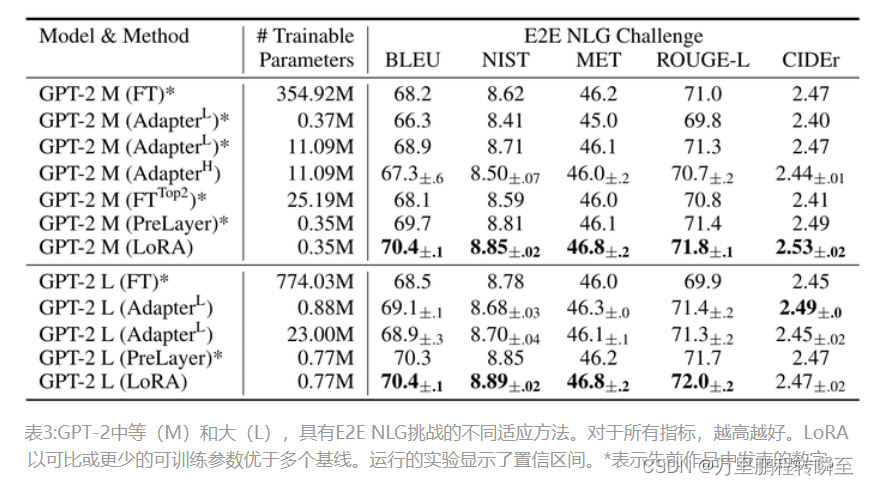
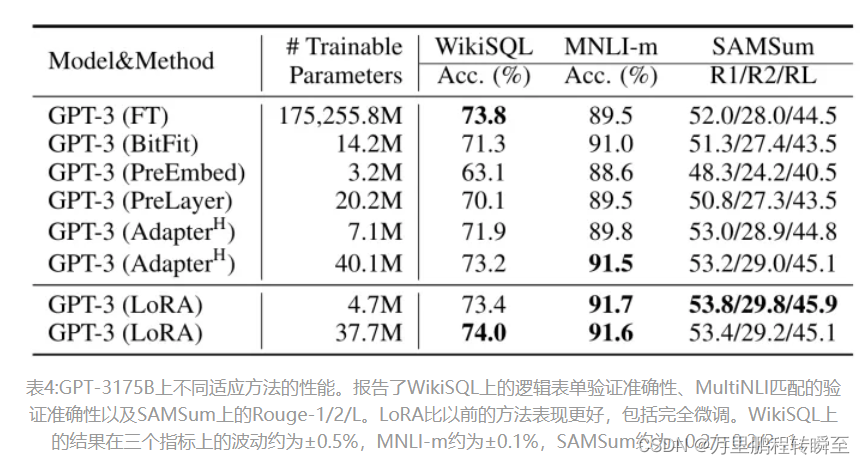
2.3 低秩结构的有效性
低秩结构在机器学习中非常常见。许多机器学习问题具有一定的内在低秩结构。此外,众所周知,对于许多深度学习任务,尤其是那些具有严重过参数化神经网络的任务,经过训练后,学习的神经网络将具有低秩属性。以前的一些工作甚至在训练原始神经网络时明确施加了低秩约束;然而,据我们所知,这些工作中没有一项考虑低秩更新到冻结模型以适应下游任务。在理论文献中,已知当基础概念类具有一定的低秩结构时,神经网络优于其他经典学习方法,包括相应的(有限宽度)神经正切核。Allen Zhu&Li(2020b)的另一个理论结果表明,低秩的适应对对抗性训练很有用。文章来源:https://uudwc.com/A/y5PZm
这里所透露出的低秩结构与Criss-Cross Attention有点类似,其也与深度可分卷积存在某些相似。将模型的fineturn空间限定在原有参数的低秩子空间下(该操作必然会影响模型性能,但是将通用模型迁移到专业领域本质就是在降低原有模型的能力范围),在低秩范围优化参数,然后在适用到原有参数空间。文章来源地址https://uudwc.com/A/y5PZm

